ㅁCPU: 적은 수의 강력한 ALU(산술 논리 장치)를 포함하여, 복잡한 작업을 빠르게 처리하는 데 최적화되어 있다. CPU는 제어 유닛과 캐시, DRAM을 통해 다양한 작업을 효과적으로 관리한다.
ㅁGPU: 많은 수의 작은 코어(core)를 가지고 있어서, 병렬 연산을 통해 대량의 데이터를 동시에 처리하는 데 최적화되어 있다.

ㅁCUDA(Compute Unified Device Architecture): NVIDIA에서 개발한 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델로, GPU(Graphics Processing Unit)를 활용하여 고성능 연산을 수행할 수 있게 하는 기술이다. 일반적으로 CPU만으로 수행하기 힘든 대규모 연산을 GPU의 수많은 코어를 통해 병렬 처리함으로써 성능을 크게 향상시킬 수 있다.
CUDA는 특히 딥러닝, 인공지능, 과학 시뮬레이션, 영상 처리 등의 고성능 컴퓨팅 분야에서 많이 활용되며, 사용자는 C, C++, Python 등의 언어를 통해 CUDA API를 호출하여 GPU 연산을 수행할 수 있다. GPU의 각 코어가 독립적으로 연산을 수행하므로 반복적이고 병렬화가 가능한 작업에 특히 적합하다.
CUDA의 주요 요소에는 스레드, 워프(warp), 블록(block), 그리드(grid) 등이 있으며, 이들은 GPU 자원을 효율적으로 사용하기 위한 계층적 구조로 설계되어 있다.

Host 코드는 CPU에서 실행되고, Parallel 코드는 GPU에서 병렬로 실행된다. CUDA C/C++ 애플리케이션은 CPU와 GPU 간의 협력을 통해 작업을 분산하여 병렬 처리를 최적화한다.
ㅁRAID(Redundant Array of Independent Disks): 여러 개의 하드 디스크를 하나의 디스크처럼 묶어 데이터 저장 성능과 안정성을 향상시키는 기술
[컴퓨터 구조] ep7) 보조기억장치
하드디스크와 플래시메모리같은 보조기억장치들은 개인 컴퓨터부터 서버구성 및 관리까지 다방면으로 사용되는 부품이기 때문에 잘 알아놔야 한다 ㅇ하드디스크 (HDD: Hard Disk Drive)하드디스
claremont.tistory.com
SIMD와 SIMT는 둘 다 병렬 컴퓨팅에서 다수의 데이터를 한 번에 처리하는 방식이다
[컴퓨터 구조] 추가지식2) SMP, 클러스터, NUMA, 클라우드 컴퓨팅
[병렬 프로세서 시스템의 유형]- 단일 명령어 + 단일 데이터 스트림: SISD(Single Instruction Single Data) - 단일 프로세서- 단일 명령어 + 다중 데이터 스트림: SIMD(Single Instruction Multiple Data) - 벡터, 배열 프
claremont.tistory.com
※ SIMD(Single Instruction, Multiple Data): 하나의 명령어로 여러 데이터를 동시에 처리하는 방식
주로 CPU에서 사용되는 병렬 처리 방식
ㅁSIMT(Single Instruction, Multiple Threads): 하나의 명령어를 여러 스레드에서 동시에 실행하는 방식
주로 GPU에서 사용되는 병렬 처리 방식

- 왼쪽: SW 구조
- Thread: CUDA에서 병렬 연산의 기본 단위 (하나의 연산을 수행하는 단일 스레드)
- Thread Block: 여러 개의 스레드가 모여 하나의 블록이 된다(블록 내 스레드들은 공유 메모리를 사용하여 서로 협력하며 작업을 수행할 수 있다)
- Grid: 여러 스레드 블록으로 구성된 단위로, 하나의 커널 함수가 실행될 때 모든 스레드 블록이 포함된 그리드가 생성된다
- 오른쪽: HW 구조
- CUDA Core: GPU의 계산 단위로, 각 스레드가 하나의 CUDA 코어에서 실행된다
- SM(Streaming Multiprocessor): 병렬 처리를 수행하는 기본 단위
SM은 여러 스레드가 동시에 작업을 처리할 수 있는 다수의 코어로 구성되어 있다. 그리고 GPU는 여러 개의 이 SM을 가지고 있어 다량의 데이터를 동시에 처리할 수 있다. (각 Thread Block은 각 SM(Streaming Multiprocessor)에 분배되어 실행)
- Device: GPU 전체를 의미하며, 여러 SM을 포함하여 대규모 병렬 처리를 수행할 수 있다.

- 왼쪽: Host(CPU)
CPU에서 커널을 호출하여 GPU(Device)에서 병렬 처리를 수행하도록 요청
- 오른쪽: Device(GPU)
- Grid: 커널 실행 시 생성되며, 여러 스레드 블록이 포함
- Block: 그리드 내에서 개별 단위로, 하나의 블록 내에서 여러 스레드가 동시에 실행
- Thread: 각 블록 내에서 개별 연산을 수행하는 스레드. 그림에서는 Block (1, 1) 내의 여러 스레드들을 보여주고 있다
NVIDIA A4000 GPU의 경우, 48개의 SM이 있고, SM당 128개의 CUDA 코어가 있다 (총 6144개의 CUDA 코어)
[CUDA와 RAID 환경에서 2차원 행렬 합산(2D Matrix Summation)을 시뮬레이션하는 작업의 세부 사항]
CUDA 기반의 SM 간 데이터 분산 및 수집 작업과 RAID의 데이터 저장 방식을 시뮬레이션(데이터 처리 성능과 입출력 효율을 분석)
// 2D matrix summation
// CPU 기반의 행렬 합산 코드: A와 B라는 두 입력 행렬을 더해 C라는 결과 행렬에 저장
float* ia = A;
float* ib = B;
float* ic = C;
for (int iy = 0; iy < ny; iy++) {
for (int ix = 0; ix < nx; ix++) {
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
// CUDA를 사용한 병렬 행렬 합산 코드: A와 B라는 두 입력 행렬을 더해 C라는 결과 행렬에 저장
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x; // ix: 스레드의 2D 인덱스 계산
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y; // iy: 스레드의 2D 인덱스 계산
unsigned int idx = iy * nx + ix; // idx: 1D 배열 인덱스로 변환한 값
if (ix < nx && iy < ny) {
MatC[idx] = MatA[idx] + MatB[idx];
}
Client: SM(Streaming Multiprocessor)
Server: 데이터를 저장하고 관리하는 역할을 수행하는 엔티티로 설정된 시뮬레이션
• 8개의 SM을 가정(이 시뮬레이션에서는 8개의 SM이 각기 병렬로 작업을 수행한다 가정)
• Input은 128 x 128 2D integer로 구성(16K of integer = 64KB): 입력 데이터로 사용되는 2D 행렬은 128 x 128 크기의 정수형 데이터로, 총 16,384개 정수 (16KB)로 이루어져 있으며, 전체 크기는 64KB
(SM에 주어진 2개의 크기로 분산)
(1) 8 x 8: 2D 행렬을 8 x 8 크기의 데이터 블록으로 분할하여 각 SM에 분배(전달)
(2) 4 x 4: 2D 행렬을 4 x 4 크기의 데이터 블록으로 분할하여 각 SM에 분배(전달)
• 각 Client(SM)는 자신에게 할당된 데이터 블록을 처리하고, 연속된 data로 모은 후 두 server로 보낸다
• 각 Server는 각 Client(SM)로부터 총 1K개의 integer(4KB 크기의 데이터 블록)씩 받아서 저장한다 (이때, I/O block size = 4KB로 설정)
※ Client(SM)에서 연속된 데이터를 수집하는데 사용되는 통신 기법과 Client(SM)에서 Server로 데이터를 전송하는 통신 기법이 서로 달라야 한다
(이 조건은 통신 방법의 차이로 인해 발생하는 성능 차이를 분석하는 데에 목적)
※ 편의상 Client(SM)와 Server는 실제 시스템이 아닌 파일 시스템으로 구성되어 시뮬레이션 되며, Client(SM)에서 데이터를 분산 및 수집한 데이터와 Server에 저장된 결과를 od 명령어를 사용해 파일을 확인함으로써 dump(출력)해줘야 한다 (디버깅 및 시각화)
(1) 16 x 16 크기의 행렬을 8 x 8 파티셔닝으로 나눈 후 각 부분을 8개의 SM(Streaming Multiprocessor)에 분배

각 SM은 8 x 8 크기의 데이터 블록을 하나씩 처리하며, 계산이 동시에 수행되어 빠른 결과를 얻을 수 있다
(2) 16 x 16 크기의 행렬을 4 x 4 파티셔닝으로 나눈 후 각 부분을 8개의 SM(Streaming Multiprocessor)에 분배

4 x 4 파티셔닝의 장점
- 세분화된 작업: 8 x 8 파티셔닝보다 작은 단위로 나누었기 때문에, 각 SM에 더 많은 병렬 작업을 부여하여 GPU 자원을 더욱 효율적으로 사용할 수 있다.
- 병렬 처리 최적화: 더 작은 4 x 4 블록 단위로 처리함으로써, 병렬 작업의 효율을 극대화할 수 있다.
[각 Client(SM)가 처리한 데이터가 Server에 전송되는 방법]

각 Client(SM)의 도메인 크기는 총 데이터의 양을 클라이언트 수로 나눈 값
- server (0): SM(0), SM(1), SM(4), SM(5)의 데이터를 수신하여 저장
- server (1): SM(2), SM(3), SM(6), SM(7)의 데이터를 수신하여 저장
server (0)과 server (1)은 각기 네 개의 SM으로부터 데이터를 받아 저장하며, 이를 통해 데이터가 병렬로 처리되고 효과적으로 분산 저장된다
[각 Server가 Client(SM)로부터 데이터를 받아 저장하는 방식] (이 그림에서는 I/O 블록 크기가 64개의 integer로 설정)

목적
- 이 방식은 데이터를 효율적으로 분산하고, 병렬 처리 효율을 높이기 위한 분산 저장 구조를 시뮬레이션하는 것
- 각 서버가 클라이언트로부터 데이터 블록을 번갈아 수신하므로, 작업이 분산되어 I/O 성능이 최적화된다.
(8 x 8 파티셔닝과 4 x 4 파티셔닝에 따른 각 통신 및 I/O 시간의 비교)
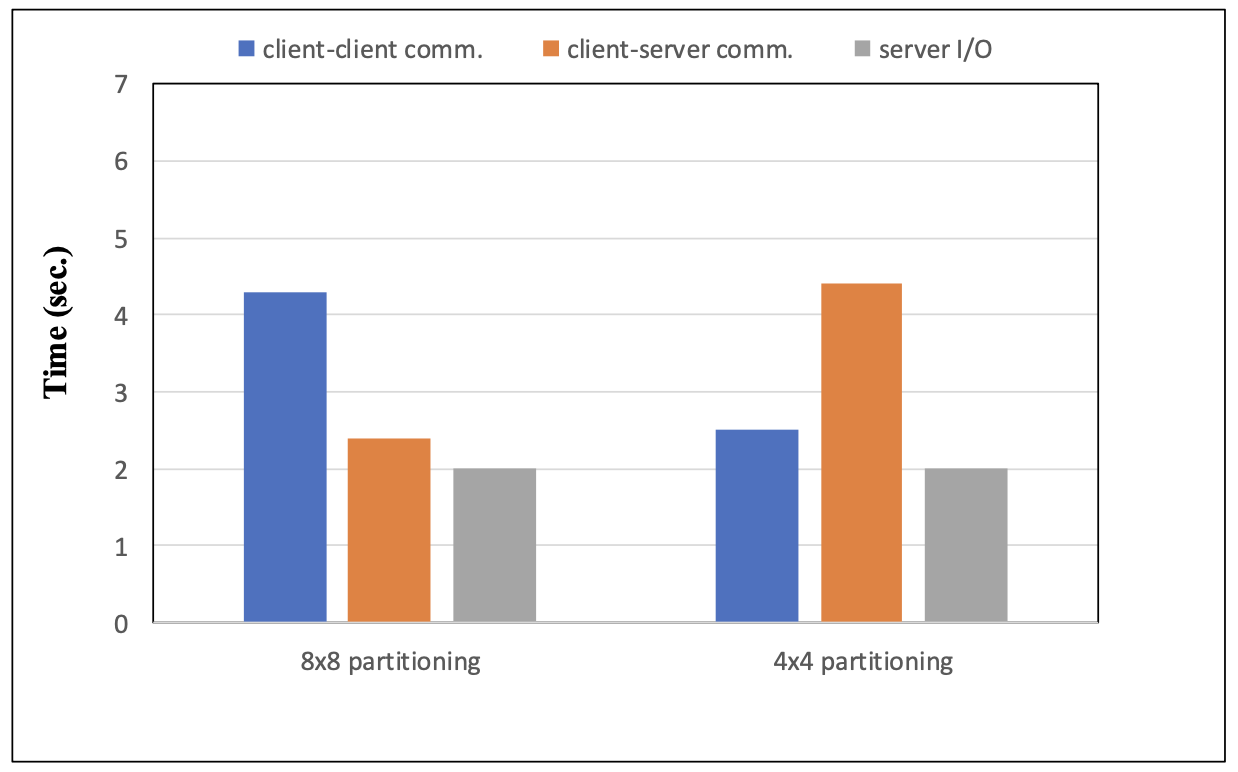
- 8 x 8 파티셔닝: client-client 간 통신 시간 bad, client-server 간 통신 시간 good. (클라이언트 간의 통신이 빈번한 경우에 유리)
- 4 x 4 파티셔닝: client-client 간 통신 시간 good, client-server 간 통신 시간 bad. (∵ 파티셔닝 단위가 작아져 클라이언트 간 통신이 줄어들고, 서버와의 통신이 많아졌기 때문)
'Computer Science > UNIX & Linux' 카테고리의 다른 글
| [UNIX/Linux] ep7++) 레코드 락킹(advisory locking) (0) | 2024.11.06 |
|---|---|
| [UNIX/Linux] ep9+) 파이프 함수 실습 (0) | 2024.11.04 |
| [UNIX/Linux] ep9) 파이프 (0) | 2024.10.31 |
| [UNIX/Linux] ep8+) 시그널 함수 실습 (1) | 2024.10.24 |
| [UNIX/Linux] ep8) 시그널 (0) | 2024.10.23 |



