문제1) 두 개의 집합 A와 B를 입력받아, A가 B의 부분집합인지를 검사하는 프로그램을 작성하라
1) 집합은 오름차순 양의 정수로 저장 및 출력되어야 한다.
2) 공집합은 공집합을 포함한 모든 집합의 부분집합이다.
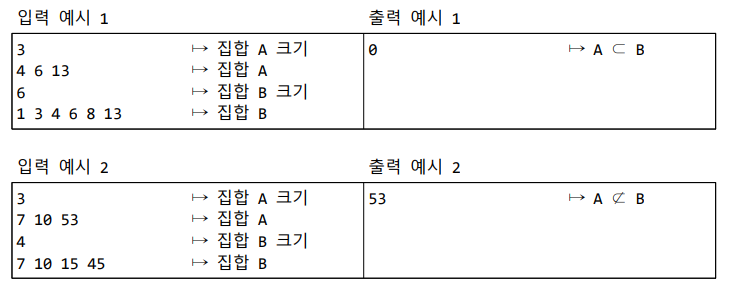
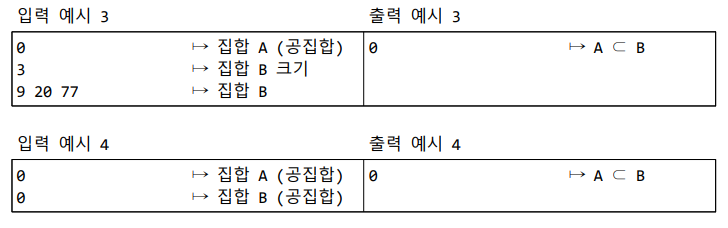
3) 입력: 프로그램은 두 개의 집합 A, B를 차례로 표준입력받는다. 한 개의 집합을 나타내는 두 개의 입력 라인은 다음과 같이 구성된다. 첫 번째 라인: 정수 n (집합 크기, 즉 집합 원소의 개수) 두 번째 라인: 집합의 원소들 (오름차순 양의 정수 수열). 공집합은 첫 번째 라인은 0, 두 번째 라인은 존재하지 않는다.
4) 출력: A ⊂ B이면 0을 출력하고, 그렇지 않으면 B에 속하지 않은 A의 가장 작은 원소를 표준 출력한다.
5) 모든 집합은 헤더 노드가 없는 단일연결리스트(singly-inked list) 형태로 구축되어야 한다.
다음 함수를 작성하여 사용하시오.
subset(A, B): 집합 A가 집합 B의 부분집합인지 여부 검사
- 인자: 양의 정수 집합 A, B (A, B는 각각 단일연결리스트의 헤드 노드)
- 반환값: 정수 (A ⊂ B면 0, 그렇지 않으면 B에 속하지 않은 A의 가장 작은 원소)
(전체코드)
// 모든 집합은 헤더 노드가 없는 단일연결리스트로 구축해야 한다
#include <stdio.h>
#include <stdlib.h>
#pragma warning (disable : 4996)
typedef struct NODE {
int val;
struct NODE* next;
} NODE;
int subset(NODE* A, NODE* B);
int main() {
int n;
NODE* headA = (NODE*)malloc(1 * sizeof(NODE));
headA->next = NULL;
NODE* headB = (NODE*)malloc(1 * sizeof(NODE));
headB->next = NULL;
NODE* cur;
int res;
scanf("%d", &n);
if (n != 0) { // 집합 A가 공집합이 아닌 경우
cur = headA;
for (int i = 0; i < n; i++) {
NODE* newNode = (NODE*)malloc(1 * sizeof(NODE));
newNode->next = NULL;
scanf("%d", &newNode->val);
cur->next = newNode;
cur = newNode;
}
}
scanf("%d", &n);
if (n != 0) { // 집합 B가 공집합이 아닌 경우
cur = headB;
for (int i = 0; i < n; i++) {
NODE* newNode = (NODE*)malloc(sizeof(NODE));
newNode->next = NULL;
scanf("%d", &newNode->val);
cur->next = newNode;
cur = newNode;
}
}
res = subset(headA, headB);
printf("%d\n", res);
while (headA != NULL) {
NODE* temp = headA;
headA = headA->next;
free(temp);
}
while (headB != NULL) {
NODE* temp = headB;
headB = headB->next;
free(temp);
}
return 0;
}
int subset(NODE* A, NODE* B) {
NODE* headA = A;
NODE* headB = B;
// A를 기준으로 A보다 큰 B원소가 나올 때 까지 돌린다, 나오면 headA = headA->next
while (headA != NULL) {
if (headB == NULL || headA->val < headB->val) { // 조건식은 A의 현재 요소가 B에 존재하지 않음을 의미
return headA->val; // B에 속하지 않은 A의 가장 작은 원소
}
else if (headA->val > headB->val) {
headB = headB->next;
}
else if (headA->val == headB->val) {
headA = headA->next;
headB = headB->next;
}
}
return 0; // A는 B의 부분집합
}
문제2) 두 개의 집합을 입력받아, 합집합과 교집합을 구하는 프로그램을 작성하라
1) 모든 집합은 오름차순 양의 정수로 저장 및 출력되어야 한다.
2) 공집합 처리에 주의
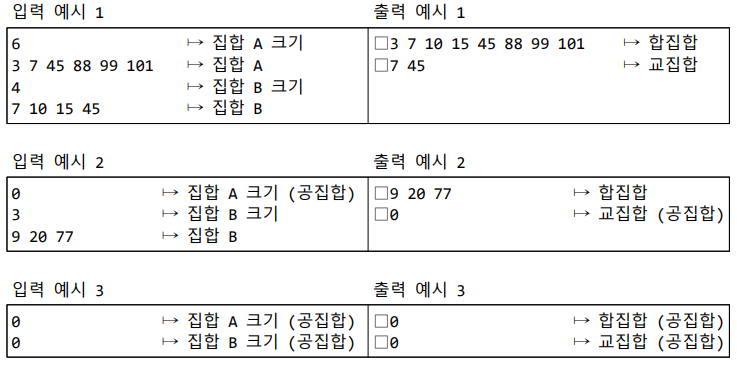
3) 입력: 프로그램은 두 개의 집합 A, B를 차례로 표준입력받는다. 한 개의 집합을 나타내는 두 개의 입력 라인은 다음과 같이 구성된다. 첫 번째 라인: 정수 n (집합 크기, 즉 집합 원소의 개수) 두 번째 라인: 집합의 원소들 (오름차순 양의 정수 수열). 따라서 공집합은 첫 번째 라인은 0, 두 번째 라인은 존재하지 않는다.
4) 출력: 각 연산 결과는 두 개의 라인으로 표준출력한다. 첫 번째 라인은 합집합을, 두 번째 라인은 교집합을 나타낸다. 이때 공집합은 0으로 출력한다.
5) 모든 집합은 헤더(header) 노드가 추가된 단일연결리스트 형태로 구축되어야 한다.
다음 함수를 작성하여 사용하시오.
union(A, B): 합집합 연산
- 인자: 양의 정수 집합 A, B (A, B는 각각 헤더 단일연결리스트의 헤더 노드)
- 반환값: A∪B의 헤더 노드 주소 또는, 공집합인 경우 빈 리스트(즉, 헤더 노드만 존재)
intersect(A, B): 교집합 연산
- 인자: 양의 정수 집합 A, B (A, B는 각각 헤더 단일연결리스트의 헤더 노드)
- 반환값: A∩B의 헤더 노드 주소 또는, 공집합인 경우 빈 리스트(즉, 헤더 노드만 존재)
(전체코드)
// 모든 집합은 헤더 노드가 추가된 단일연결리스트로 구축해야 한다
#include <stdio.h>
#include <stdlib.h>
#pragma warning (disable : 4996)
typedef struct NODE {
int val;
struct NODE* next;
} NODE;
NODE* insert(NODE* head, int val);
void printList(NODE* head);
NODE* ft_union(NODE* A, NODE* B);
NODE* intersect(NODE* A, NODE* B);
int main() {
int n;
NODE* A = NULL;
NODE* B = NULL;
int val;
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%d", &val);
A = insert(A, val);
}
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%d", &val);
B = insert(B, val);
}
NODE* unionResult = ft_union(A, B);
NODE* intersectResult = intersect(A, B);
if (unionResult == NULL) {
printf(" 0\n");
}
else {
printList(unionResult);
}
if (intersectResult == NULL) {
printf(" 0\n");
}
else {
printList(intersectResult);
}
while (A != NULL) {
NODE* temp = A;
A = A->next;
free(temp);
}
while (B != NULL) {
NODE* temp = B;
B = B->next;
free(temp);
}
while (unionResult != NULL) {
NODE* temp = unionResult;
unionResult = unionResult->next;
free(temp);
}
while (intersectResult != NULL) {
NODE* temp = intersectResult;
intersectResult = intersectResult->next;
free(temp);
}
return 0;
}
NODE* insert(NODE* head, int val) {
NODE* newNode = (NODE*)malloc(1 * sizeof(NODE));
newNode->val = val;
newNode->next = NULL;
if (head == NULL) {
head = newNode;
}
else {
NODE* cur = head;
while (cur->next != NULL) {
cur = cur->next;
}
cur->next = newNode;
}
return head;
}
void printList(NODE* head) {
while (head != NULL) {
printf(" %d", head->val);
head = head->next;
}
printf("\n");
}
NODE* ft_union(NODE* A, NODE* B) {
NODE* res = NULL;
NODE* cur;
cur = res;
while (A != NULL || B != NULL) {
if (A == NULL) { // A가 공집합인 case
cur = insert(cur, B->val);
B = B->next;
}
else if (B == NULL) { // B가 공집합인 case
cur = insert(cur, A->val);
A = A->next;
}
else if (!(A == NULL && B == NULL)) { // 평상시 case
if (A->val < B->val) {
cur = insert(cur, A->val);
A = A->next;
}
else if (A->val > B->val) {
cur = insert(cur, B->val);
B = B->next;
}
else if (A->val == B->val) {
cur = insert(cur, A->val);
A = A->next;
B = B->next;
}
}
if (res == NULL) { // 새로운 노드가 삽입되어 처음으로 res가 생성될 때! 이 경우에는 res가 NULL이므로 cur값을 대입해 줘서 첫 번째 헤드를 가리키게 한다
res = cur;
}
else { // 평상시
cur = cur->next;
}
}
return res;
}
NODE* intersect(NODE* A, NODE* B) {
NODE* res = NULL;
NODE* cur;
cur = res;
while (A != NULL && B != NULL) {
if (A->val < B->val) {
A = A->next;
}
else if (A->val > B->val) {
B = B->next;
}
else if (A->val == B->val) {
cur = insert(cur, A->val);
A = A->next;
B = B->next;
if (res == NULL) { // res가 여전히 NULL이면 발견된 첫 번째 공통 요소라는 의미이므로, res를 cur에 할당하여 res가 첫 번째 공통 노드를 가리키도록 한다
res = cur;
}
else {
cur = cur->next;
}
}
}
return res;
}
/*
입력 예시1)
6
3 7 45 88 99 101
4
7 10 15 45
출력 예시1)
3 7 10 15 45 88 99 101
7 45
입력 예시2)
0
3
9 20 77
출력 예시2)
9 20 77
0
입력 예시3)
0
0
출력 예시3)
0
0
*/
참고 및 출처: 데이터 구조 원리와 응용(국형준교수님)
'Computer Science > 자료구조' 카테고리의 다른 글
| [자료구조] ep5+) 심볼 균형(스택을 이용한 괄호 쌍의 대칭성 검사) (0) | 2024.06.08 |
|---|---|
| [자료구조] ep5) 스택(Stack) (0) | 2024.06.07 |
| [자료구조] ep4) 집합(Set) (0) | 2024.05.03 |
| [자료구조] ep3-3) 다중연결리스트(Multi Linked List) (0) | 2024.05.03 |
| [자료구조] ep3-2) 이중연결리스트(Double Linked List) (0) | 2024.05.03 |



