ㅁRDB(Relational DataBase): 관계형 데이터베이스
키(key)와 값(value)을 테이블 형태로 구성한 데이터베이스

[데이터베이스] ep1) DB 모델
ㅁ논리적 데이터 모델들1. 계층형 데이터 모델 2. 네트워크형 데이터 모델 3. 관계형 데이터 모델(RDB: Relational DataBase)- 우리는 이 RDB에 대해 앞으로 지겹도록 다룰 것이다 ㅁRDB 데이터 모
claremont.tistory.com
[릴레이션의 특성]
튜플의 유용성: 하나의 릴레이션에 동일한 튜플 존재 불가
튜플의 무순서: 하나의 릴레이션에서 튜플 사이의 순서 무의미
속성의 무순서: 하나의 릴레이션에서 속성 사이의 순서 무의미
속성의 원자성: 속성값으로 원자값(하나의 값)만 사용 가능
ㅇ키(key): 릴레이션에서 튜플들을 유일하게 구별하는 속성 또는 속성들의 집합

5가지 종류가 있다
1. 슈퍼키(Super Key): 유일성

2. 후보키(Candidate Key): 유일성 + 최소성

(중요)3. 기본키(PK, Primary Key): 후보키 중 기본키로 선택
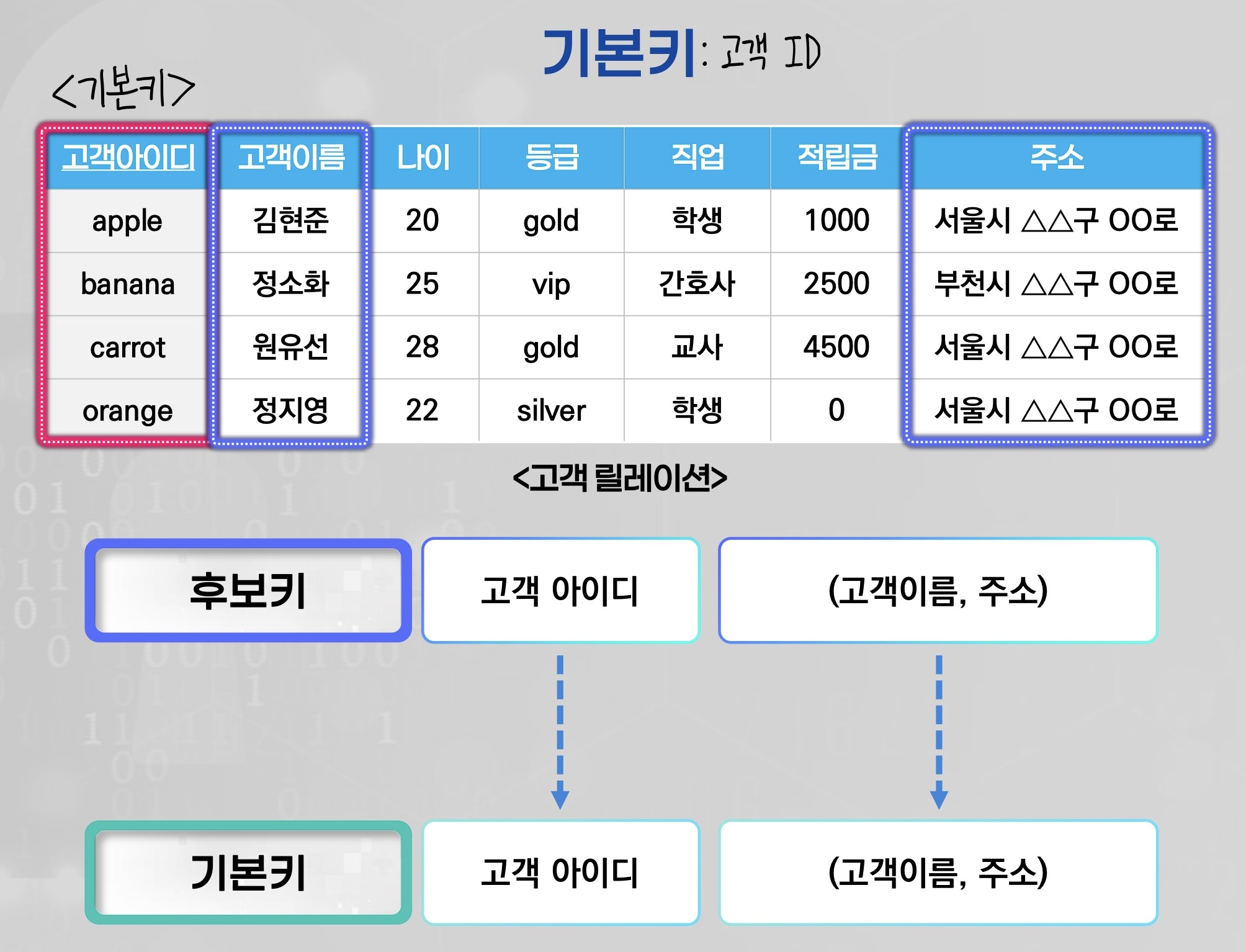
4. 대체키(Alternate Key): 후보키 중 기본키로 선택 X

(중요)5. 외래키(FK, Foreign Key): “다른 릴레이션의 기본키”를 참조하는 속성 or 속성들의 집합

ㅇ데이터 무결성 제약 조건 3가지
1. 엔티티(개체) 무결성 제약 조건: 기본키는 NULL 값을 가지면 안 되며 릴레이션 내에 오직 하나의 값만 존재해야 한다
기본키 제약
2. 도메인 무결성 제약 조건: 릴레이션 내 튜플들이 각 속성의 도메인에 지정된 값을 가져야 한다
도메인 제약 (속성값과 관련된 무결성)
3. 외래키(참조) 무결성 제약 조건
자식 릴레이션 외래키 = 부모 릴레이션 기본키와 도메인
부모 릴레이션 도메인과 다른 값으로 삽입/수정할 경우 거부
자식 릴레이션에서 참조하고 있는 값을 부모 릴레이션에서 삭제/수정할 경우 거부
(참고)
현업에서는 성능문제 때문에 외래키 제약 조건을 안쓰는 경우가 더 많다고 한다
e.g. Insert 성능 저하
ㅁ관계 대수(Relation Algebra)
일반 집합 연산자: 릴레이션이 튜플의 집합이라는 개념 이용
순수 관계 연산자: 릴레이션의 구조와 특성을 이용

ㅇSelect 연산자(σ): 조건을 만족하는 튜플만 선택하여 결과 릴레이션을 구성

ㅇProject 연산자(π): 선택한 속성의 값으로 결과 릴레이션을 구성

ㅇDivision 연산자: 릴레이션1 / 릴레이션2
릴레이션 2의 모든 튜플과 관련이 있는 릴레이션 1의 튜플로 결과 릴레이션을 구성

ㅇCartesian Product 연산자: R X S
릴레이션 R에 속한 각 튜플과 릴레이션 S에 속한 각 튜플을 모두 연결하여 만들어진 새로운 튜플로 결과 릴레이션을 구성
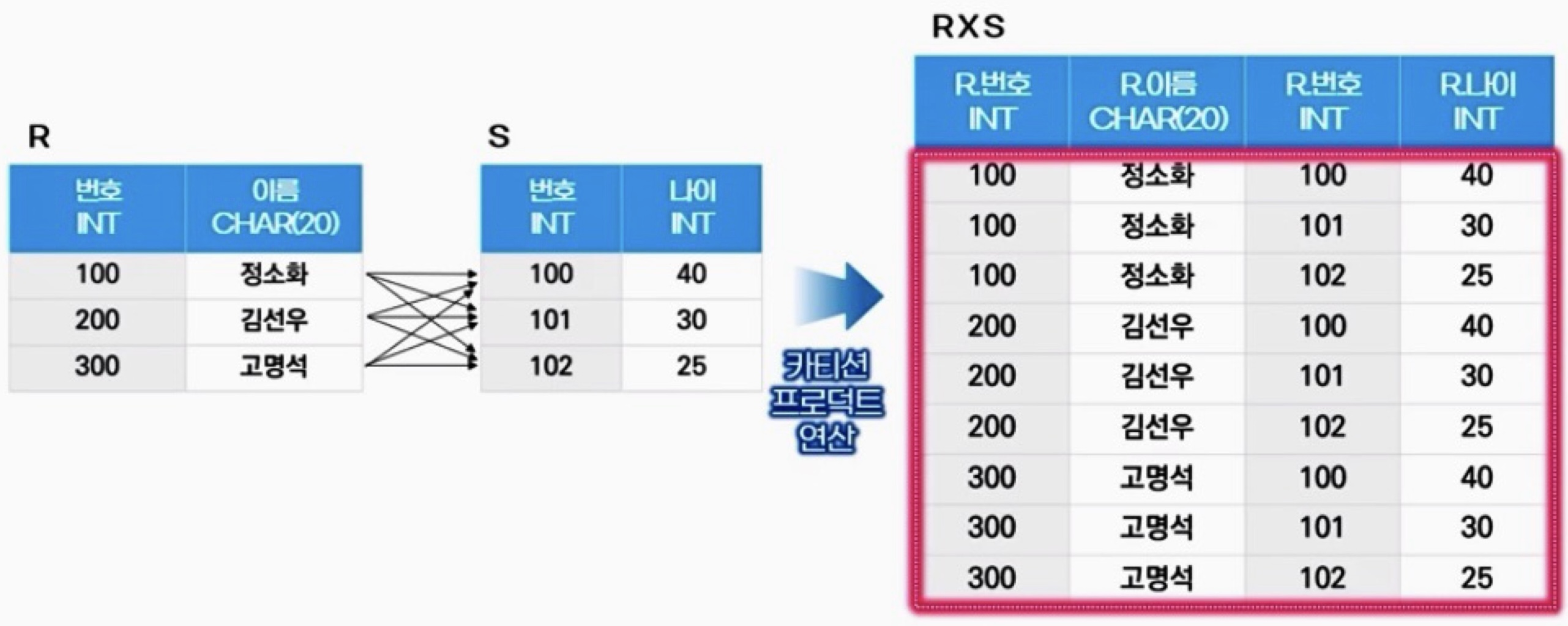
차수 = R 차수 + S 차수
카디널리티 = R 카디널리티 x S 카디널리티
교환법칙 ㅇ, 결합법칙 ㅇ
ㅇUnion 연산자: R U S (합집합)
릴레이션 R 또는 릴레이션 S에 속하는 모든 튜플로 결과 릴레이션을 구성
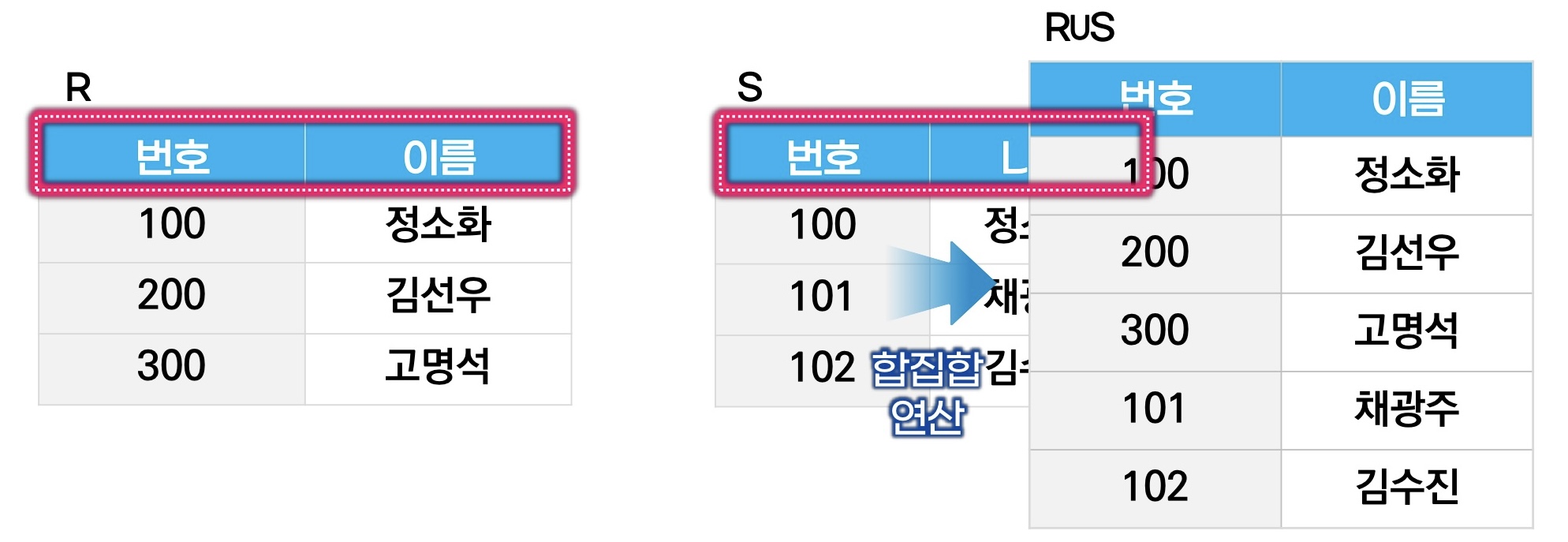
차수는 그대로
카디널리티 <= R 카디널리티 + S 카디널리티
교환법칙 ㅇ, 결합법칙 ㅇ
ㅇIntersection 연산자: R ∩ S (교집합)
릴레이션 R과 S에 공통으로 속하는 튜플로 결과 릴레이션을 구성

차수는 그대로
카디널리티는 릴레이션 R과 S의 어떤 카디널리티보다 같거나 적음
교환법칙 ㅇ, 결합법칙 ㅇ
ㅇDifference 연산자: R - S (차집합)
릴레이션 R에는 존재하지만 릴레이션 S에는 존재하지 않는 튜플로 결과 릴레이션을 구성

차수는 그대로
R-S 카디널리티 <= R
S-R 카디널리티 <= S
교환법칙 x, 결합법칙 x (순서 바꾸면 큰일 난다!)
ㅇJoin 연산자: R ⨝ S
조인 속성의 값이 같은 튜플만 연결하여 생성된 튜플을 결과 릴레이션에 포함

+ 동등조인(equal-join): R = S
+ 자연조인: 중복된 속성이 한 번만 결과 릴레이션에 나타나는 것
출처 및 참고: 세종대학교 K-MOOC 데이터베이스 보안(김영갑)
'DBMS > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] ep4-2) SQL: DML (0) | 2024.06.29 |
|---|---|
| [데이터베이스] ep4-1) SQL: DDL (0) | 2024.06.21 |
| [데이터베이스] ep2) DBMS (1) | 2024.06.20 |
| [데이터베이스] ep1) DB 모델 (0) | 2024.05.03 |
| [데이터베이스] ep0) 파일시스템 vs 데이터베이스 (1) | 2024.05.03 |



