[생성형 AI] 자연어 처리(NLP, Natural Language Processing) 개념
ㅁ자연어 처리(NLP, Natural Language Processing): 컴퓨터가 인간의 언어(자연어)를 이해하고 처리할 수 있도록 하는 기술텍스트 데이터에서 의미를 추출하고, 문장을 생성하는 등의 작업을 수행하며,
claremont.tistory.com
https://claremont.tistory.com/entry/%EC%83%9D%EC%84%B1%ED%98%95-AI-Transformer-%EA%B5%AC%EC%A1%B0
[생성형 AI] Transformer 구조
https://claremont.tistory.com/entry/LLM-LLM-%EB%B0%B0%EA%B2%BD-%EB%B0%8F-%EA%B5%AC%EC%A1%B0-%EC%9D%B4%ED%95%B4 [생성형 AI] 자연어 처리(NLP, Natural Language Processing) 개념ㅁ자연어 처리(NLP, Natural Language Processing): 컴퓨터가
claremont.tistory.com
ㅁGPT(Generative Pre-trained Transformer): OpenAI에서 개발한 대규모 언어 모델로, Transformer 구조를 기반으로 한 자연어 생성(NLG, Natural Language Generation) 모델

사전 학습(Pre-training)과 미세 조정(Fine-tuning) 과정을 거쳐 다양한 자연어 처리(NLP) 작업을 수행할 수 있다.
[GPT의 Decoder 아키텍처]
- Masked Self-Attention : 다음 단어를 예측하는 과정에서 미래 단어 정보를 참조하지 않도록 마스킹을 적용한다
- Feed Forward Network(FFN) : 각 단어 벡터를 더욱 깊이 변환하는 신경망 레이어이다
- Layer Normalization : 학습 안정성을 높이고, 학습 속도를 빠르게 한다
- Residual Connection : 신경망의 깊이가 깊어질수록 발생하는 기울기 소실 문제를 해결한다
(GPT의 2단계 학습 과정)
① 사전 학습(Pre-training): 대량의 텍스트 데이터를 이용하여 언어 모델을 학습
이 과정에서 GPT는 다음 단어 예측(Next Token Prediction)을 목표로 한다 e.g. "나는 학교에" → "간다" 를 예측
※ Self-Attention을 활용하여 문맥을 이해하는 능력을 습득
② 파인 튜닝(Fine-tuning, 미세 조정): 사전 학습된 모델을 특정 작업
예를 들어서 챗봇, 문서 요약, 코드 생성 등에 맞춰 추가 학습을 한다
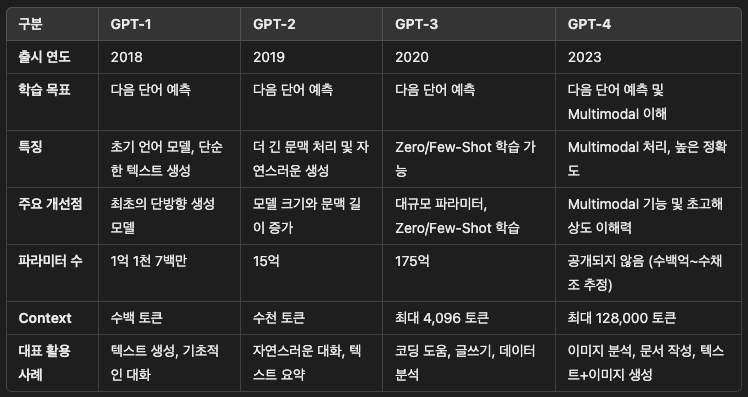
[GPT 버전별 특징 비교]
[딥러닝] 파라미터(parameter)란?
ㅁ파라미터(parameter): 머신러닝과 딥러닝 모델에서 학습을 통해 조정되는 값을 의미다시 말하면, 인공지능 모델이 입력 데이터를 처리하면서 출력을 결정하는 가중치(weight)와 편향(bias) 등의 값
claremont.tistory.com
(GPT의 주요 활용 사례)
1. 챗봇(Chatbot)
고객 지원, 상담 서비스 등에 사용
2. 기계 번역(Machine Translation)
문맥을 고려한 자연스러운 번역 수행
3. 코드 생성(Code Generation)
GitHub Copilot, OpenAI Codex와 같은 프로그래밍 보조 도구로 활용
4. 문서 요약(Text Summarization)
긴 문서를 간결하게 요약하는 기능 제공
5. 감성 분석(Sentiment Analysis)
리뷰나 댓글에서 긍정/부정 감정을 분석
(GPT의 한계점 3가지)
1. 정보의 신뢰성 문제
학습된 데이터에 따라 사실과 다른 정보를 생성할 가능성이 있다
2. 문맥 유지의 한계
긴 문장에서는 앞 문맥을 잊어버리는 문제가 발생할 수 있다
3. 편향(Bias) 문제
훈련 데이터에 포함된 사회적 편향(Bias)이 모델에도 반영될 수 있다
GPT는 Transformer 기반의 강력한 자연어 생성 모델로, 다양한 NLP 작업에서 혁신적인 성능을 보여주고 있다. 특히 Self-Attention 메커니즘을 활용한 문맥 이해 능력이 뛰어나며, 챗봇, 번역, 문서 요약 등 다양한 분야에서 활용되고 있다. 그러나 신뢰성과 편향 문제를 해결하기 위한 지속적인 연구가 필요하며, 앞으로 더욱 발전된 형태의 언어 모델이 등장할 것으로 감히 나는 예상한다!
'인공지능 > 생성형 AI' 카테고리의 다른 글
| [생성형 AI] AGI(Artificial General Intelligence): 인공지능의 최종 목표 (1) | 2025.02.17 |
|---|---|
| [생성형 AI] LLM의 Tool Calling(도구 호출)이란? (0) | 2025.02.17 |
| [생성형 AI] RAG (Retrieval-Augmented Generation) 개요 (0) | 2025.02.17 |
| [생성형 AI] Transformer 구조 (0) | 2025.02.16 |
| [생성형 AI] 자연어 처리(NLP, Natural Language Processing) 개념 (0) | 2025.02.14 |



