순회(traversal): 트리의 노드들을 체계적인 방식으로 방문하는 것을 의미
트리의 주요 순회로는 크게 3가지가 있고 추가적인 순회로 또 2가지가 더 있다
1. 선위순회(predorder traversal): Root > Left > Right
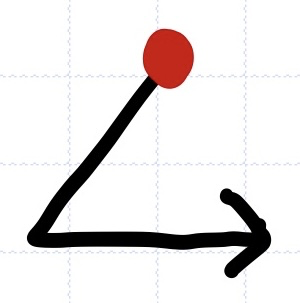
응용: 구조적 문서를 인쇄, 계층적 파일 시스템의 모든 폴더들을 나열

void preorderTraversal(NODE* node) { // 재귀적 성질을 이용한다
if (node == NULL) {
return;
}
printf(" %d", node->data); // Root
preorderTraversal(node->left); // Left
preorderTraversal(node->right); // Right
}
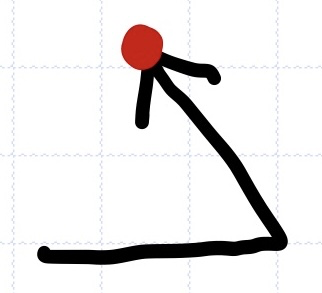
2. 중위순회(inorder traversal): Left > Root > Right
응용: 이진 트리 그리기, 수식 인쇄
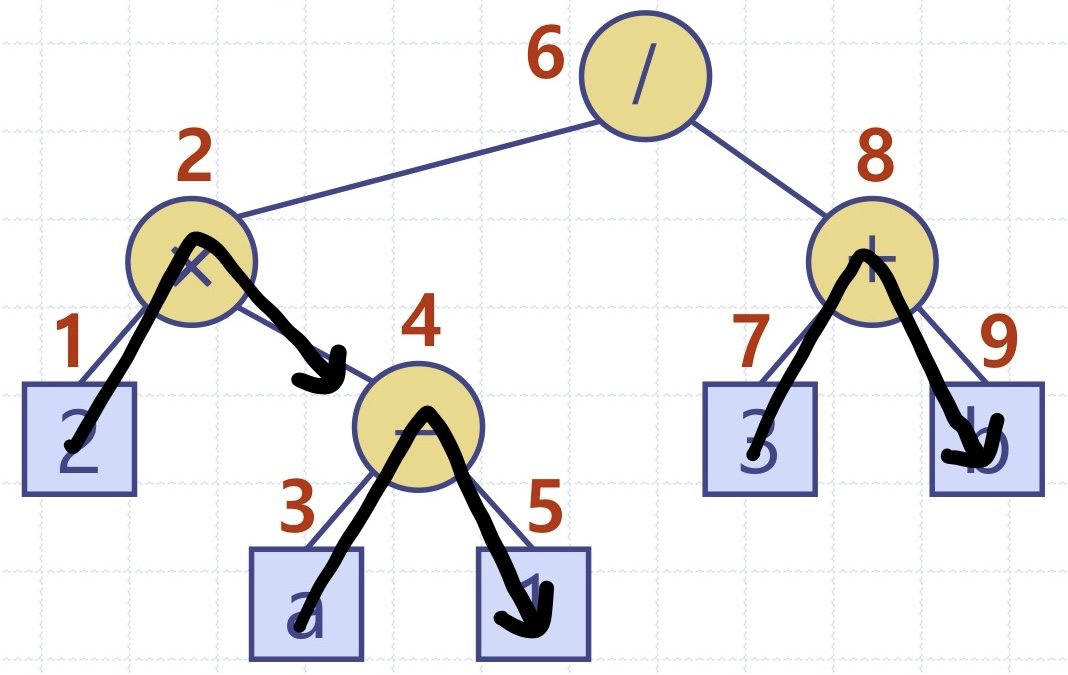
void inorderTraversal(NODE* node) { // 재귀적 성질을 이용한다
if (node == NULL) {
return;
}
inorderTraversal(node->left); // Left
printf(" %d", node->data); // Root
inorderTraversal(node->right); // Right
}
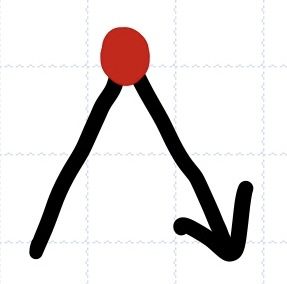
3. 후위순회(postorder traversal): Left > Right > Root
응용: 계층적 파일시스템에서 폴더의 디스크 사용량 계산
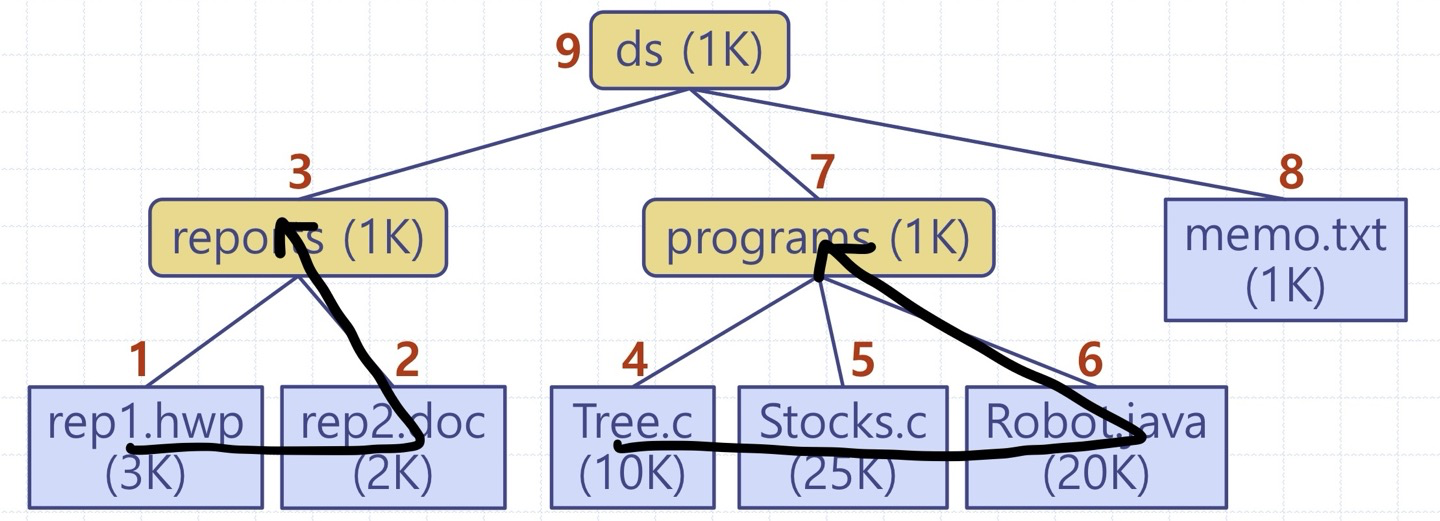
void postorderTraversal(NODE* node) { // 재귀적 성질을 이용한다
if (node == NULL) {
return;
}
postorderTraversal(node->left); // Left
postorderTraversal(node->right); // Right
printf(" %d", node->data); // Root
}
추가 2가지 순회)
4. 레벨순회(levelorder traversal): 같은 레벨의 깊이 d의 모든 노드들을 방문한 후, 그다음 깊이 d+1의 모든 노드들을 방문을 반복
"FIFO 방식의 큐를 사용해 구현"
응용: 관료적 계층구조 인쇄(e.g. 회사 직급)

주로 너비 우선 탐색(Breadth-First Search, BFS)의 한 형태로 사용.
이 방법은 그래프 탐색뿐만 아니라 트리의 각 레벨을 처리하거나 특정 수준의 노드를 찾을 때도 유용.
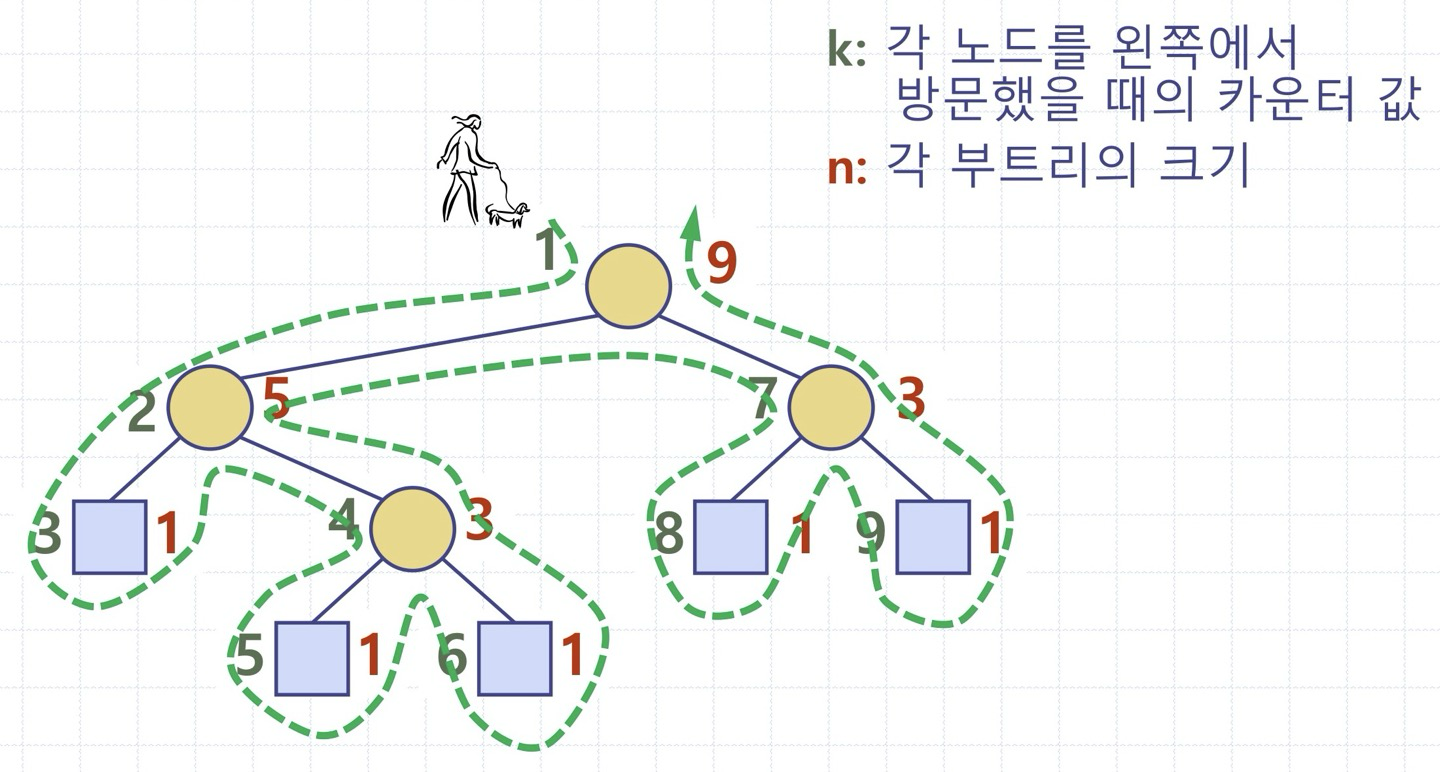
5. 오일러 투어 순회(euler tour traverse): 왼쪽 자식 방향으로 루트를 출발하여, 트리의 간선(edge)들을 항상 왼쪽 벽으로 두면서 트리 주위를 순회
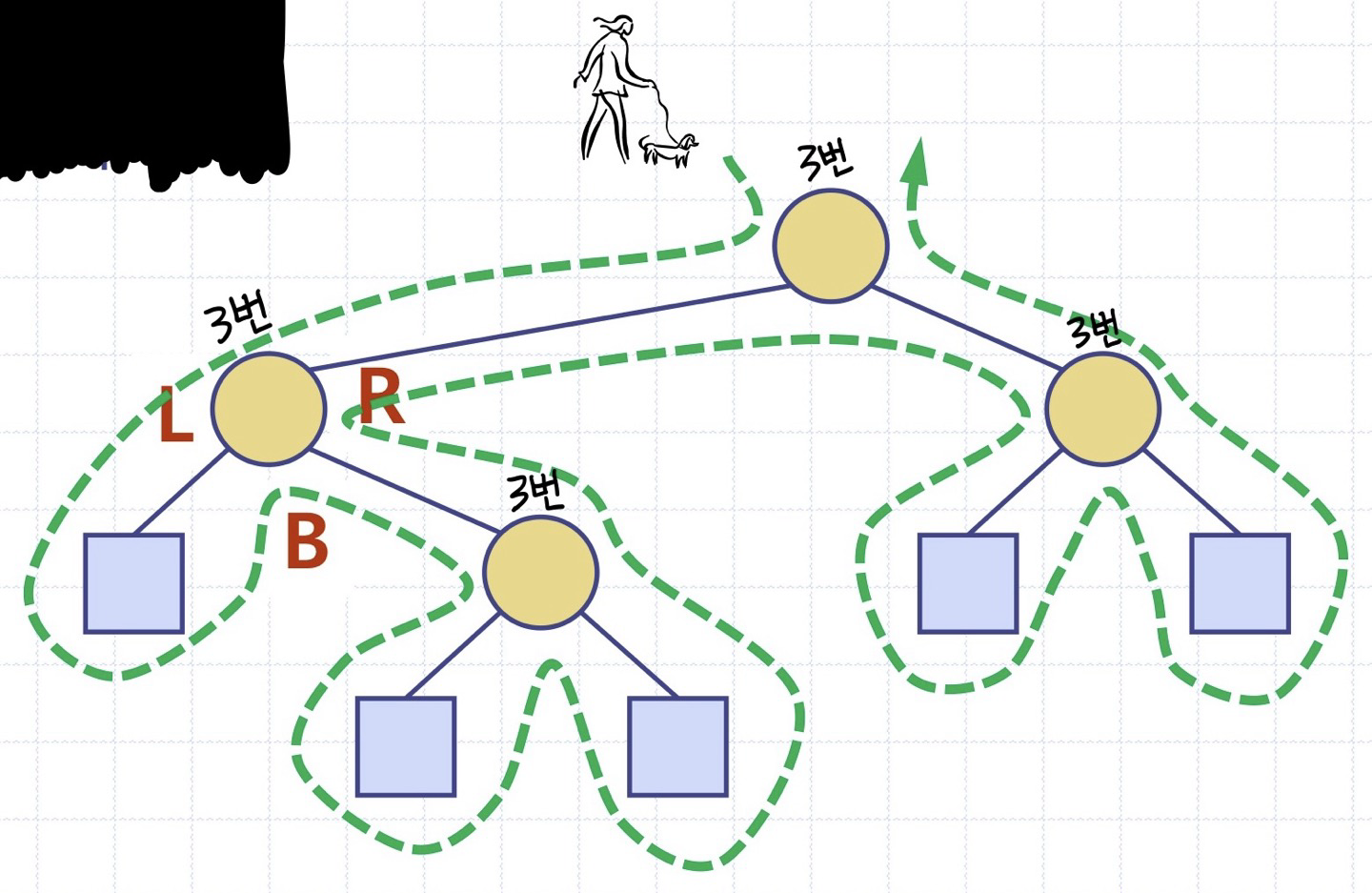
응용: 이진 트리 내 각 부트리의 노드 수 계산
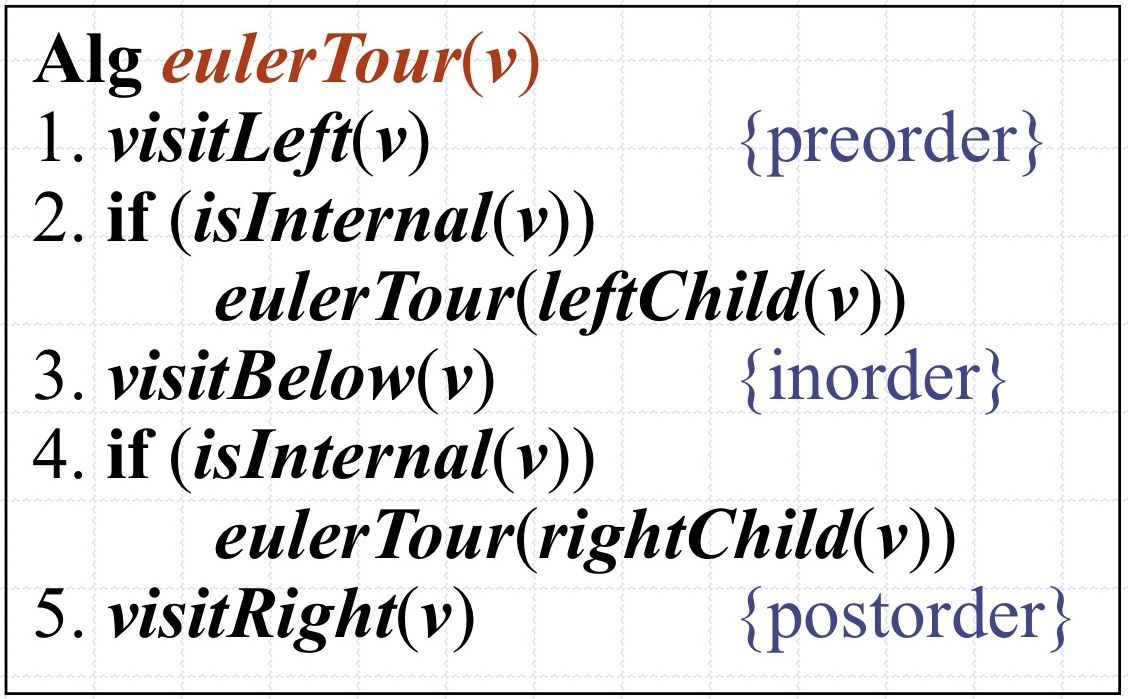

노드를 왼쪽에서 방문할 때마다 k를 하나씩 증가시킨다
루트가 v인 부트리의 크기 = (v를 왼쪽에서 방문했을 때의 k값) - (v를 오른쪽에서 방문했을 때의 k값) + 1
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
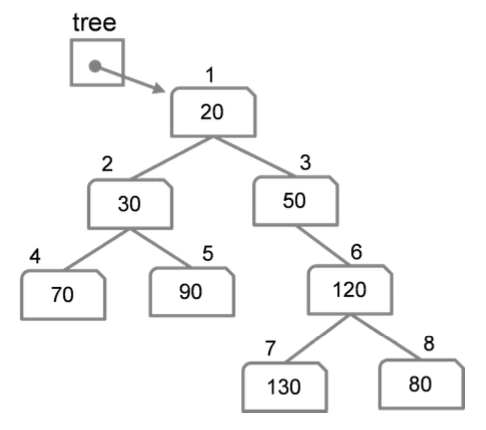
문제1) 위 트리에 대해 순회 방법과 폴더 id가 주어지면, 아래 트리의 루트노드에서 출발, 탐색하여 해당 노드를 찾고, 이 노드를 시작점으로 순회하며 각 폴더의 용량을 출력하는 프로그램을 작성하시오.
- 노드 id를 저장하기 위해 노드는 다음과 같은 구조체를 만들어 사용함.
- 이전 문제의 F1, F2와 같은 노드별 포인터는 사용할 수 없으며, 주어진 노드를 탐색하여 찾아야 함.

입출력 상세:
◦ 순회 방법 종류 (입력)
- 1: 선위순회, 2: 중위순회, 3: 후위순회
◦ 존재하지 않는 폴더 이름이 입력되는 경우 –1을 출력.


(전체 코드)
#include <stdio.h>
#include <stdlib.h>
typedef struct NODE {
int data;
int id;
struct NODE* left;
struct NODE* right;
} NODE;
NODE* newNode(int data, int id, NODE* left, NODE* right);
void preorderTraversal(NODE* node);
void inorderTraversal(NODE* node);
void postorderTraversal(NODE* node);
NODE* findNode(NODE* root, int id);
int main() {
int cmd; // 1: 선위순회, 2: 중위순회, 3: 후위순회
int id;
NODE* F7 = newNode(130, 7, NULL, NULL);
NODE* F8 = newNode(80, 8, NULL, NULL);
NODE* F6 = newNode(120, 6, F7, F8);
NODE* F3 = newNode(50, 3, NULL, F6);
NODE* F4 = newNode(70, 4, NULL, NULL);
NODE* F5 = newNode(90, 5, NULL, NULL);
NODE* F2 = newNode(30, 2, F4, F5);
NODE* F1 = newNode(20, 1, F2, F3);
scanf("%d %d", &cmd, &id);
if (id < 1 || id > 8) { // 예외처리
printf("-1\n");
return 0;
}
NODE* root = findNode(F1, id);
if (root == NULL) {
printf("-1\n");
return 0;
}
if (cmd == 1) { // 선위순회
preorderTraversal(root);
} else if (cmd == 2) { // 중위순회
inorderTraversal(root);
} else if (cmd == 3) { // 후위순회
postorderTraversal(root);
}
return 0;
}
// 노드를 생성하는 함수
NODE* newNode(int data, int id, NODE* left, NODE* right) {
NODE* newNode = (NODE*)malloc(sizeof(NODE));
newNode->data = data;
newNode->id = id;
newNode->left = left;
newNode->right = right;
return newNode;
}
// 선위순회 함수: root > left > right
// 20 -> 30 -> 70 -> 90 -> 50 -> 120 -> 130 -> 80
void preorderTraversal(NODE* node) {
if (node == NULL) {
return;
}
printf(" %d", node->data); // root
preorderTraversal(node->left); // left
preorderTraversal(node->right); // right
}
// 중위순회 함수: left > root > right
// 70 -> 30 -> 90 -> 20 -> 50 -> 130 -> 120 -> 80
void inorderTraversal(NODE* node) {
if (node == NULL) {
return;
}
inorderTraversal(node->left); // left
printf(" %d", node->data); // root
inorderTraversal(node->right); // right
}
// 후위순회 함수: left > right > root
// 70 -> 90 -> 30 -> 130 -> 80 -> 120 -> 50 -> 20
void postorderTraversal(NODE* node) {
if (node == NULL) {
return;
}
postorderTraversal(node->left); // left
postorderTraversal(node->right); // right
printf(" %d", node->data); // root
}
NODE* findNode(NODE* root, int id) {
if (root == NULL) {
return NULL;
}
if (root->id == id) {
return root;
}
NODE* foundNode = findNode(root->left, id);
if (foundNode == NULL) {
foundNode = findNode(root->right, id);
}
return foundNode;
}
문제2) 위 트리에 대해 폴더 id가 주어지면, 해당 폴더 부트리의 용량의 합을 계산하는 프로그램을 작성하시오.
◦ 트리 순회를 이용하여 구현.
◦ 합을 계산할 때 입력된 노드의 용량도 포함.
◦ 존재하지 않는 폴더 이름이 입력되는 경우 –1을 출력.

(전체 코드)
#include <stdio.h>
#include <stdlib.h>
typedef struct NODE {
int data;
int id;
struct NODE* left;
struct NODE* right;
} NODE;
NODE* newNode(int data, int id, NODE* left, NODE* right);
void preorderTraversal(NODE* node);
void inorderTraversal(NODE* node);
void postorderTraversal(NODE* node);
NODE* findNode(NODE* root, int id);
int sum = 0;
int main() {
int id;
NODE* F7 = newNode(130, 7, NULL, NULL);
NODE* F8 = newNode(80, 8, NULL, NULL);
NODE* F6 = newNode(120, 6, F7, F8);
NODE* F3 = newNode(50, 3, NULL, F6);
NODE* F4 = newNode(70, 4, NULL, NULL);
NODE* F5 = newNode(90, 5, NULL, NULL);
NODE* F2 = newNode(30, 2, F4, F5);
NODE* F1 = newNode(20, 1, F2, F3);
scanf("%d", &id);
if (id < 1 || id > 8) { // 예외처리
printf("-1\n");
return 0;
}
NODE* root = findNode(F1, id);
if (root == NULL) {
printf("-1\n");
return 0;
}
preorderTraversal(root);
printf("%d", sum);
return 0;
}
// 노드를 생성하는 함수
NODE* newNode(int data, int id, NODE* left, NODE* right) {
NODE* newNode = (NODE*)malloc(sizeof(NODE));
newNode->data = data;
newNode->id = id;
newNode->left = left;
newNode->right = right;
return newNode;
}
// 선위순회 함수: root > left > right
void preorderTraversal(NODE* node) {
if (node == NULL) {
return;
}
sum += node->data; // root
preorderTraversal(node->left); // left
preorderTraversal(node->right); // right
}
// 중위순회 함수: left > root > right
void inorderTraversal(NODE* node) {
if (node == NULL) {
return;
}
inorderTraversal(node->left); // left
sum += node->data; // root
inorderTraversal(node->right); // right
}
// 후위순회 함수: left > right > root
void postorderTraversal(NODE* node) {
if (node == NULL) {
return;
}
postorderTraversal(node->left); // left
postorderTraversal(node->right); // right
sum += node->data; // root
}
NODE* findNode(NODE* root, int id) {
if (root == NULL) {
return NULL;
}
if (root->id == id) {
return root;
}
NODE* foundNode = findNode(root->left, id);
if (foundNode == NULL) {
foundNode = findNode(root->right, id);
}
return foundNode;
}
루트 방문일 때의 코드 한 줄만 수정해 주면 된다!
참고 및 출처: 데이터 구조 원리와 응용(국형준), C언어로 쉽게 풀어 쓴 자료구조(천인국)
'Computer Science > 자료구조' 카테고리의 다른 글
| [자료구조] ep7++) 결정 트리(decision tree) - 양자택일식 문답시스템 (1) | 2024.06.11 |
|---|---|
| [자료구조] ep7+) 이진 트리 구현 및 탐색 (0) | 2024.06.11 |
| [자료구조] ep7-1) 트리(Tree) (1) | 2024.06.09 |
| [자료구조] ep6+) 두 개의 큐로 스택 설계 (1) | 2024.06.09 |
| [자료구조] ep6-3) 데크(Deque) (0) | 2024.06.09 |



